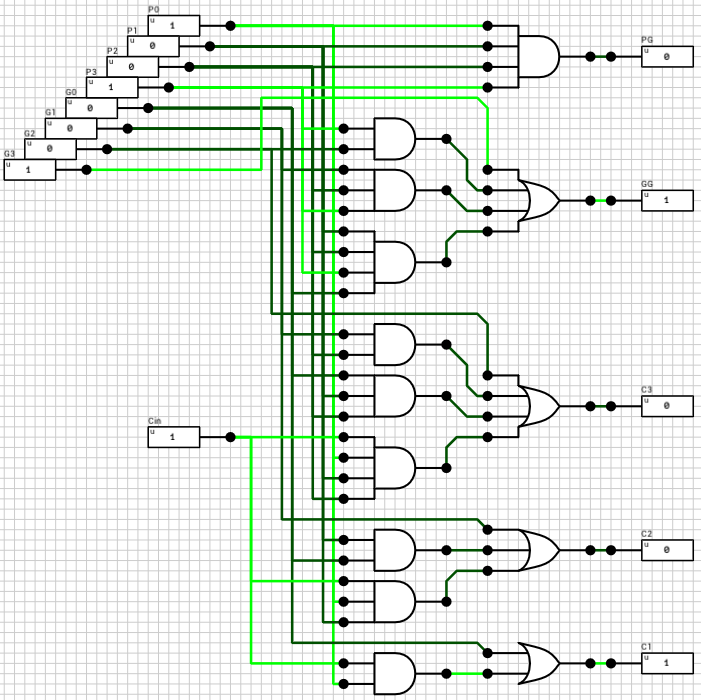
Today’s post is based on the master thesis of Arturo Barrabés Castillo titled Design of Single Precision Float Adder (32-bit Numbers) according to IEEE 754 Standard Using VHDL.
Since DLS doesn’t support more than 16 bits per wire/pin, I’ll apply the same algorithms on 16-bit floating point numbers. I kept the same component names to easily find the connection between the paper and the schematics below. There are also some differences from the paper which I’ll point out when describing the relevant part of the circuit.
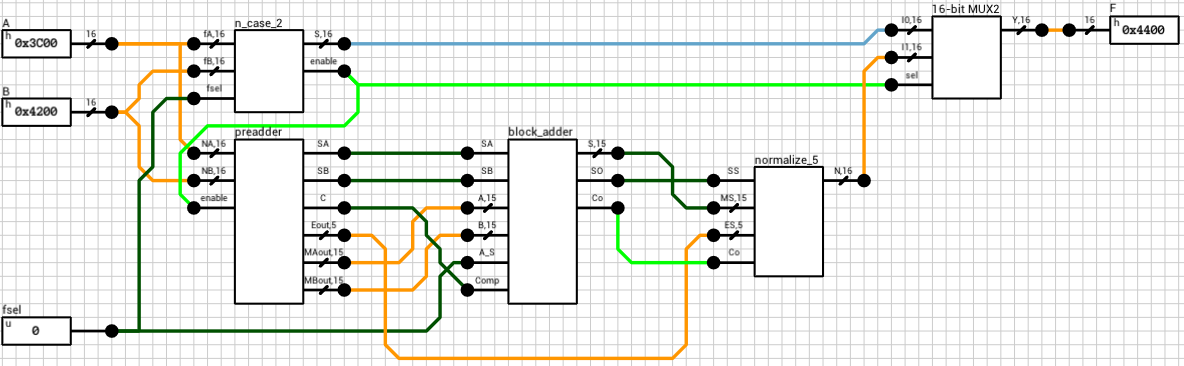
Figure 1 shows the final component. It has 3 inputs (A, B, and fsel) and 1 output (F). A and B are the two 16-bit floating point numbers. fsel is the function select signal, with 0 for addition and 1 for subtraction. F is the result of the operation.
Step 1: Check for a special case
The first step is to check if we have a special case. Special cases are considered all the cases for which the result of the operation between the 2 inputs can be determined without performing the operation. I.e. adding 0 to a number results in the number itself, adding opposite sign infinities results in a NaN, etc. (see the paper for all the cases).
The block handling this part is called n_case (figure 2). It has 2 outputs, S and enable. S is the result of the operation if a special case is detected, otherwise Undefined. enable is used to turn on the rest of the circuit in case the current combination cannot be handled by this block.
There are 2 bugs in the n_case code from the paper.
First, the classification of inputs A and B (intermediate signals outA and outB) are wrong when A or B are powers of 2 (0 < E < 255 and M = 0). Both codes on pages 22 and 96 end up producing a value of 000 for outA and outB, meaning the numbers are zero. In order to fix this problem, we just have to ignore the mantissa, in case E is in the range (0, 255) (or (0, 31) in our case of 16-bit numbers).
The second bug has to do with the treatment of B. The n_case block takes as input only the two numbers and ignores the selected operation. If fsel is 1 (subtraction), B’s sign should be reversed before checking the special cases. If we don’t do that, subtracting any number from 0 will result in the number itself, instead of its negative value (e.g. 0 - 1 = 1).
Both problems have been addressed in the circuit shown in figure 2. Other than that, the rest of the circuit consists of simple checks for each case. I decided to reverse B’s sign before making any checks, in case of subtraction. This means that 0 - 0 results in a negative zero, because the case where A is zero has higher priority than the case where B is zero. Not much of a problem, but it should be mentioned.
Step 2: Prepare for addition
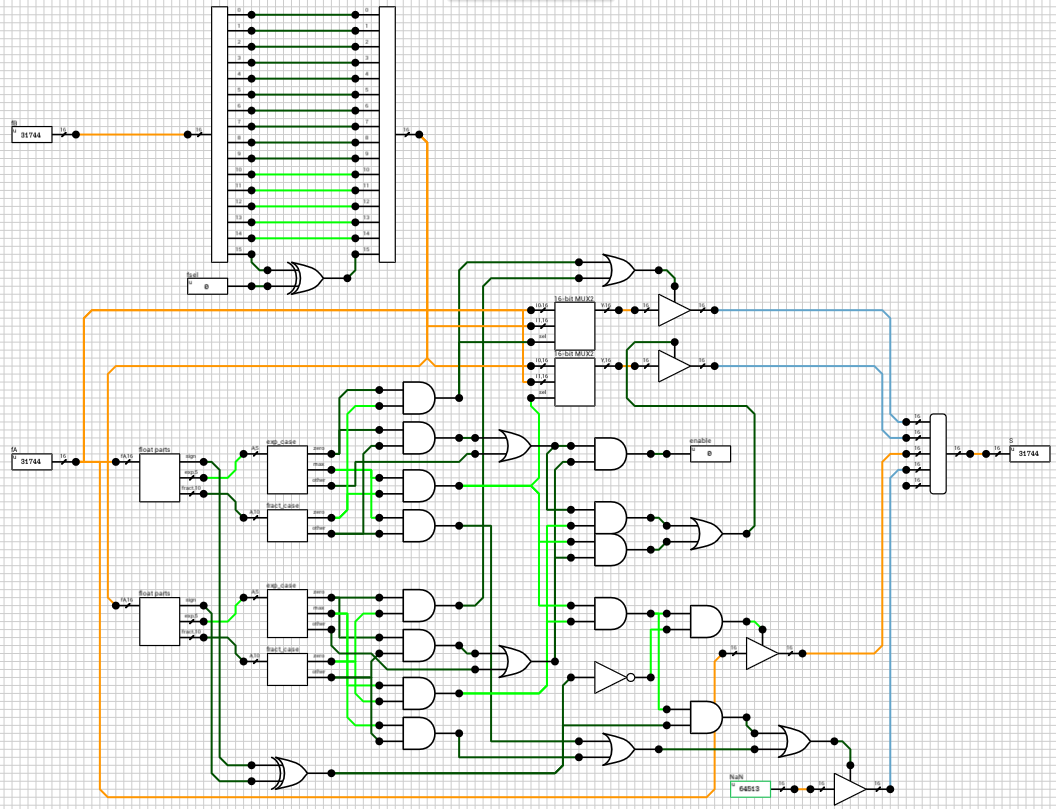
If the enable output of the n_case component is HIGH, it means that both A and B are regular numbers (normals or subnormals). Before being able to add them together, we have to align their decimal points. This is done by finding the exponent of the largest number and shifting the mantissa of the other to the right, until both exponents are equal. Remember that shifting the decimal point to the left means that the mantissa is shifted to the right. Also, for each shifted position, the exponent is incremented by 1. This part is handled by the preadder component (figure 3).
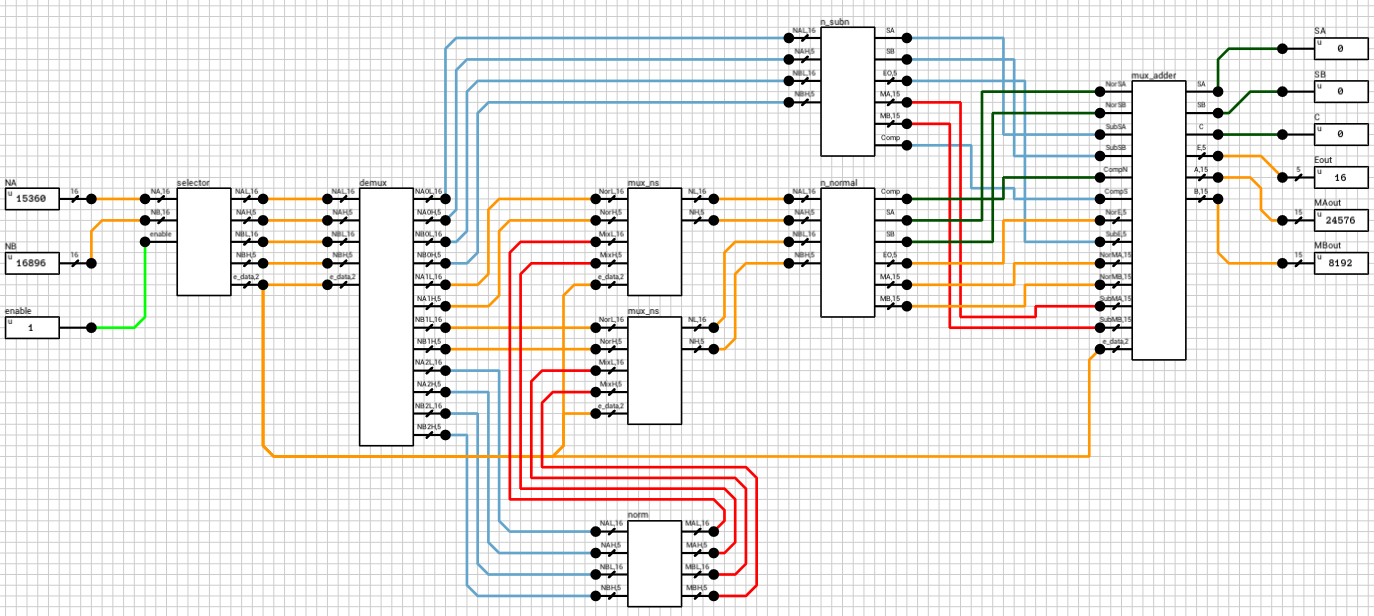
The preadder takes as input the two 16-bit numbers and the enable signal from the n_case component. First it expands both numbers to 21 bits, by introducing the implicit bit (1 for normals and 0 for subnormals) and adding 4 guard bits at the end. This is done in the selector (figure 4). The selector also outputs a 2-bit signal e_data indicating the type of both numbers (00 when both are subnormals, 01 when both are normals and 10 in case of a combination).
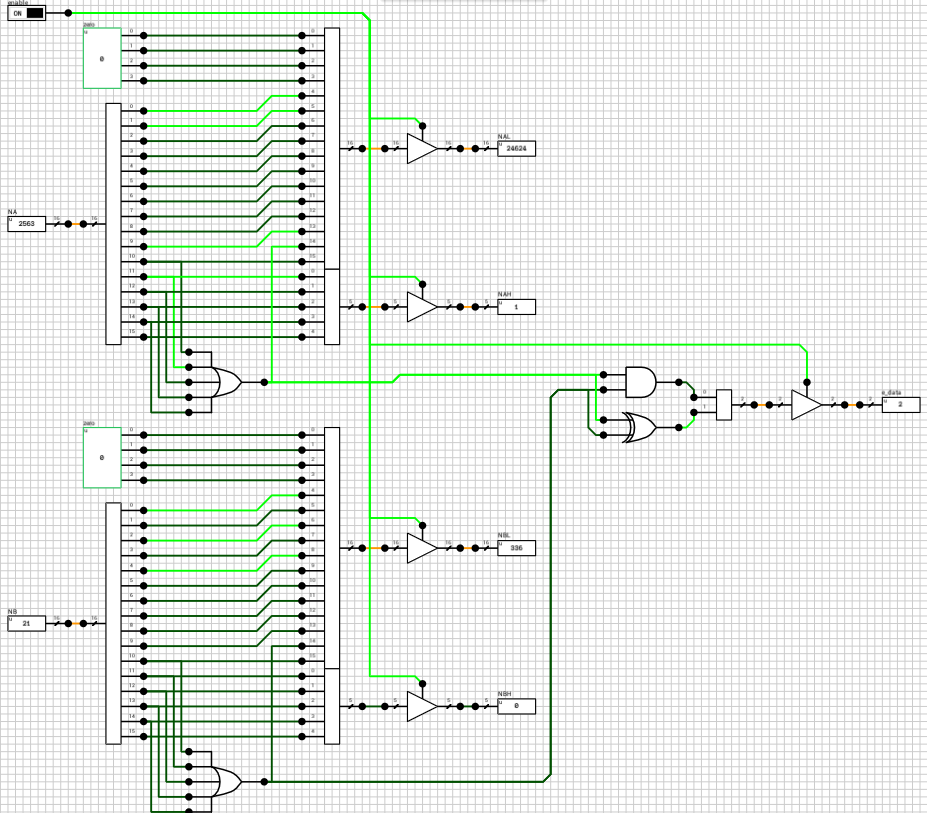
Note that the expanded 21-bit numbers are broken into 2 signals. A 16-bit for the lower part and a 5-bit signal for the higher part.
After expanding the numbers, depending on the value of e_data the correct path is chosen. If both numbers are subnormals, they are handled by the n_subn block (figure 5). In this case the output exponent is 0 (which the same for both numbers). The two mantissas are compared and the largest one is placed on MA and the other on MB. If the A input is larger than B, then Comp is HIGH, otherwise it’s LOW.
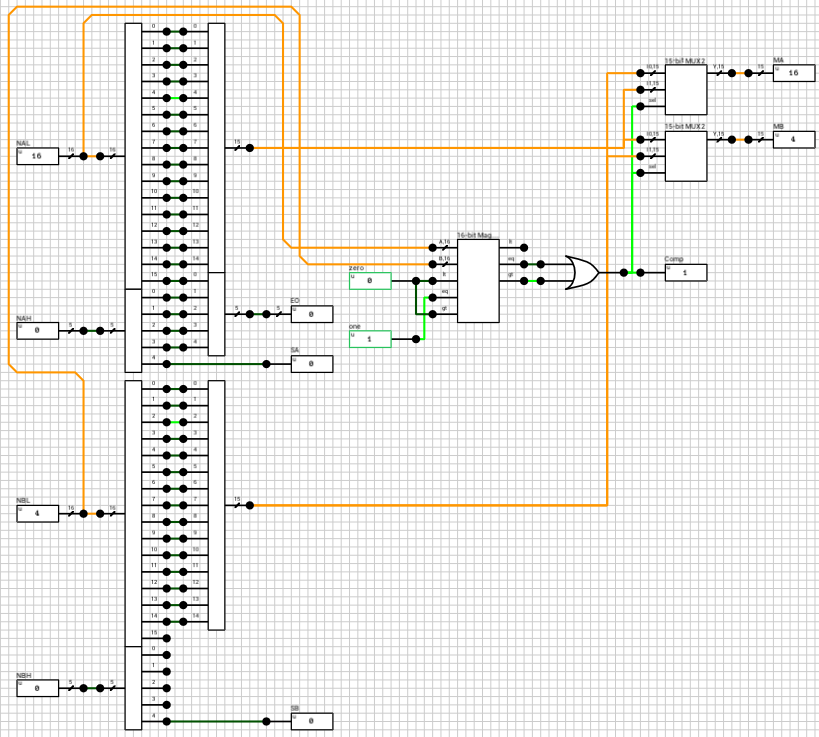
Side note: I’ve used a 16-bit magnitude comparator to compare the 2 mantissas, eventhough the extended mantissas are 15 bits wide. The 16th bit is taken from the exponent, because I know that both numbers are subnormals and thus have an exponent of zero.
If the numbers are both normals or a combination of a normal and a subnormal, they are routed to the n_normal block (figure 6 and figure 7). Again both numbers are compared and the output exponent EO is set to the largest exponent. MA holds the largest number’s mantissa. The smaller mantissa (Mshft output from the comp_exp component) is shifted to the right based on the difference of the two exponents.
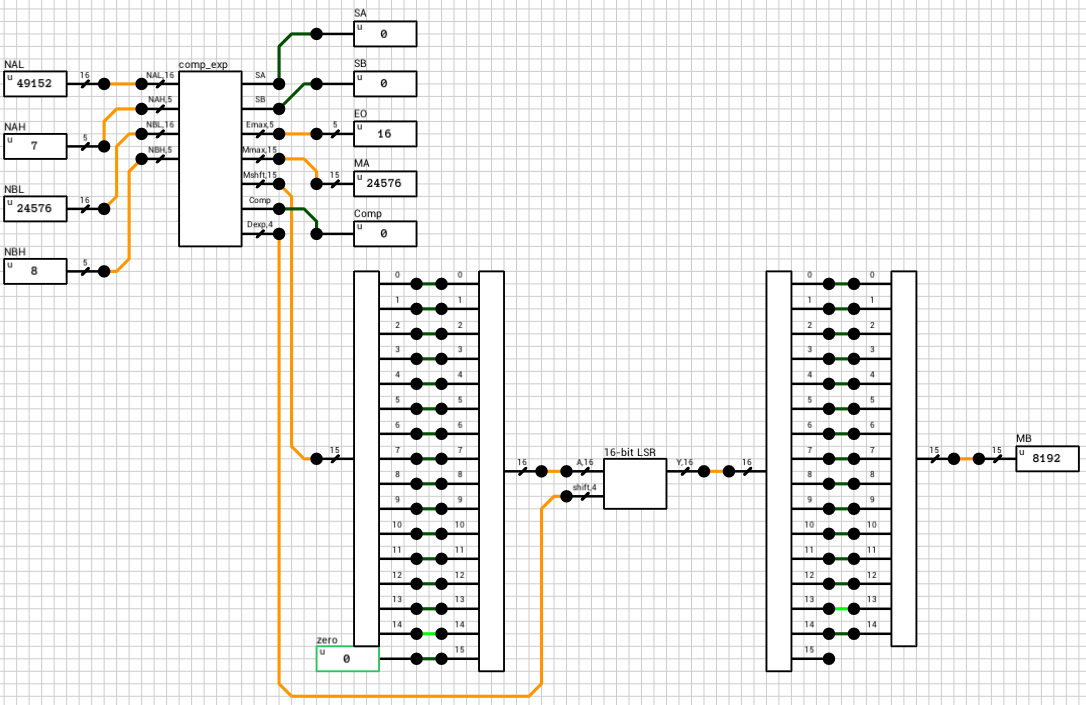
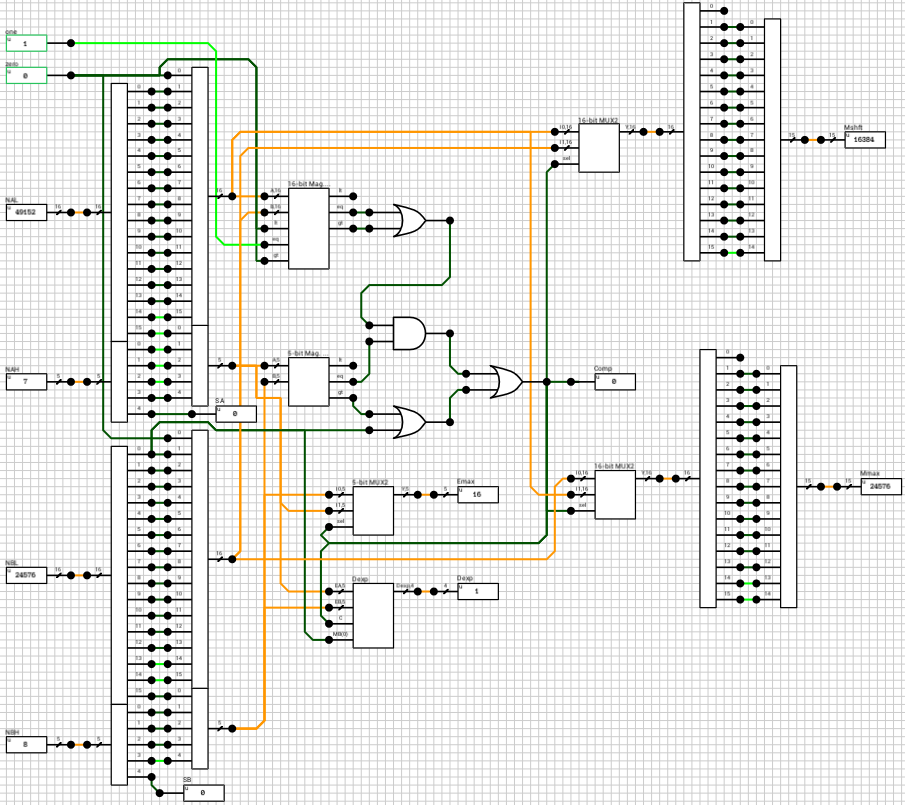
Side note: The comp_exp component uses the same 16-bit magnitude comparator as in the previous case. This time, since the exponents are non-zero, I made the 1st bit equal to 0 and the rest of the bits come from the extended mantissa.
After this step, all outputs from n_subn and n_normal are routed to the mux_adder and the final outputs of the preadder are calculated, based on e_data.
The outputs of the preadder block are the following:
SAandSB: The signs of the two numbersC: 1-bit flag indicating if number A is larger than number BEout: The final exponent, equal to the largest exponentMAout: The mantissa of the largest numberMBout: The mantissa of the smallest number
Step 3: The addition/subtraction
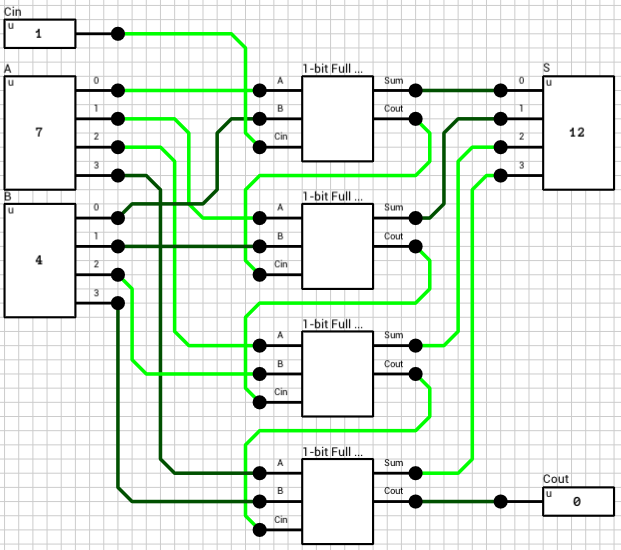
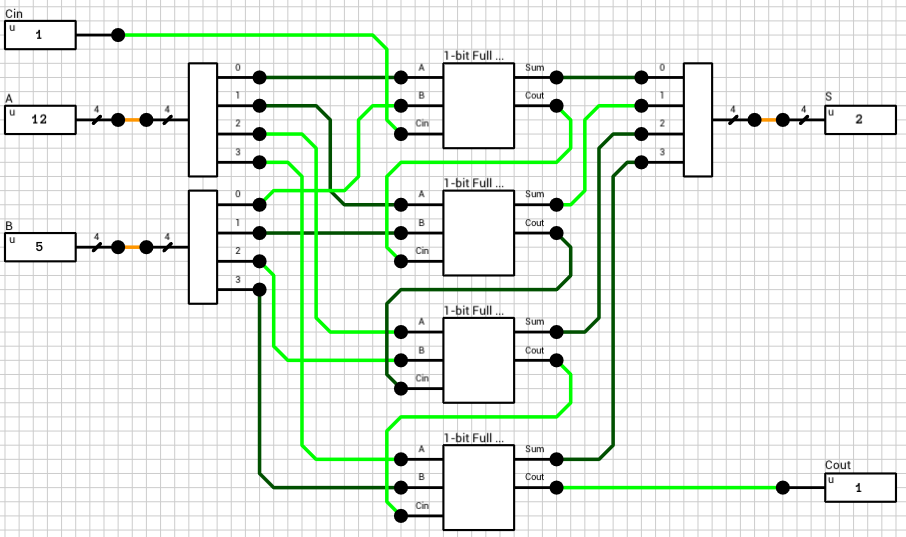
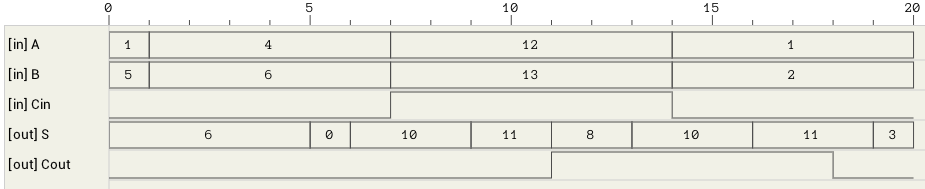
We now have both numbers in the order and the format required to perform the selected operation. Since both exponents are equal, the only thing required is to add/subtract the mantissas. This is handled by the block_adder component (figure 8). The block_adder takes as input the two signs, SA and SB, the two mantissas A and B, the selected operation (0 for addition, 1 for subtraction) and the Comp flag which indicates if A is larger than B.
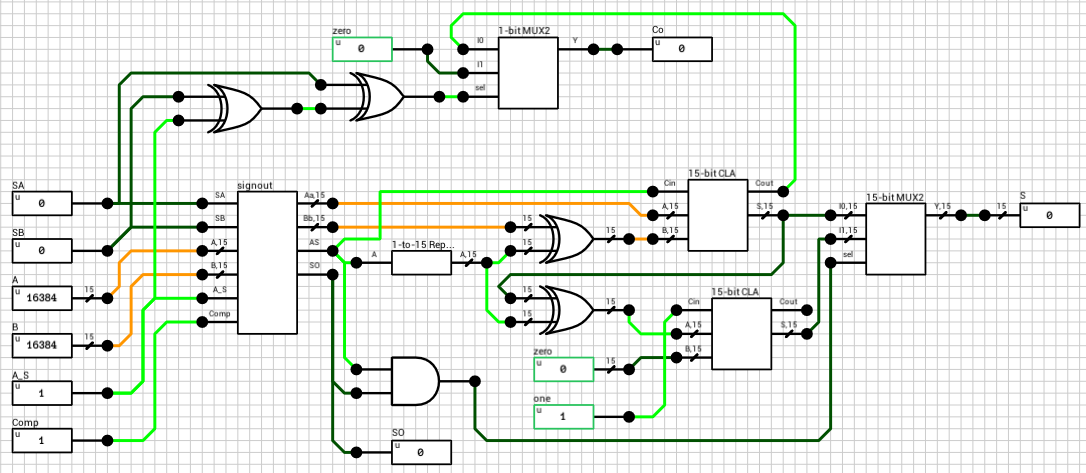
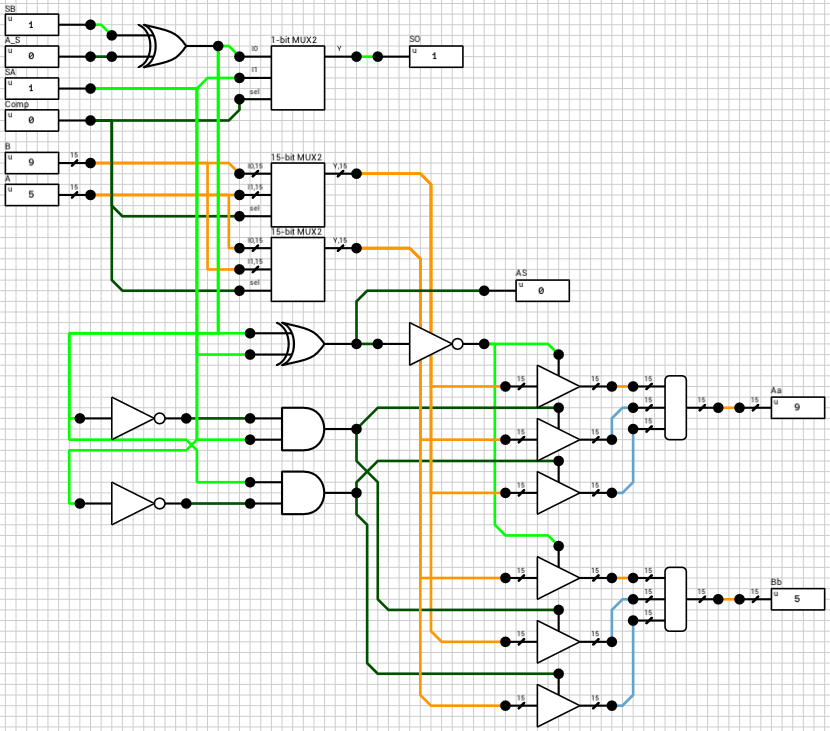
The signout block (figure 9) is responsible for calculating the sign of the result, the true operation to be performed between the two inputs and for reordering the inputs in case the true operation is different than the selected operation. The true operation is the actual operation to be performed between the two inputs. I.e. if we subtract a negative number from a positive number, the true operator is addition, which is different than the selected subtraction.
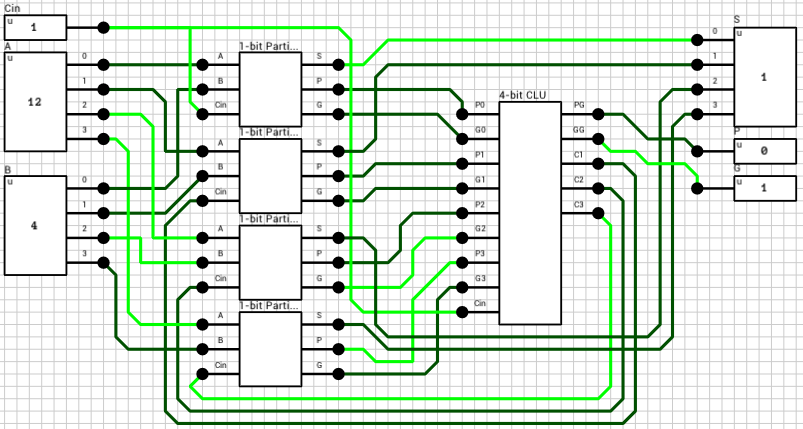
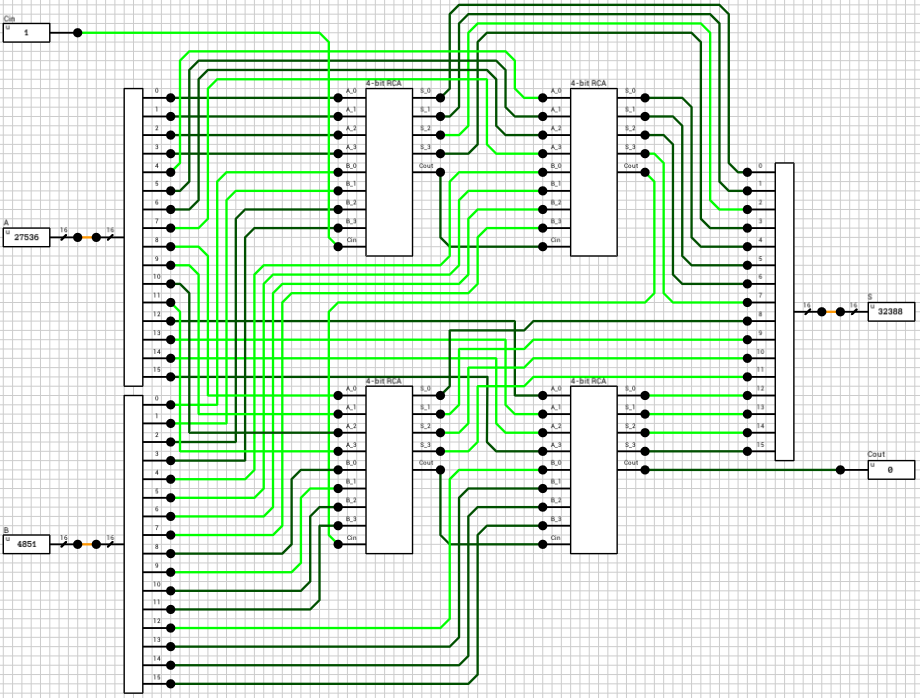
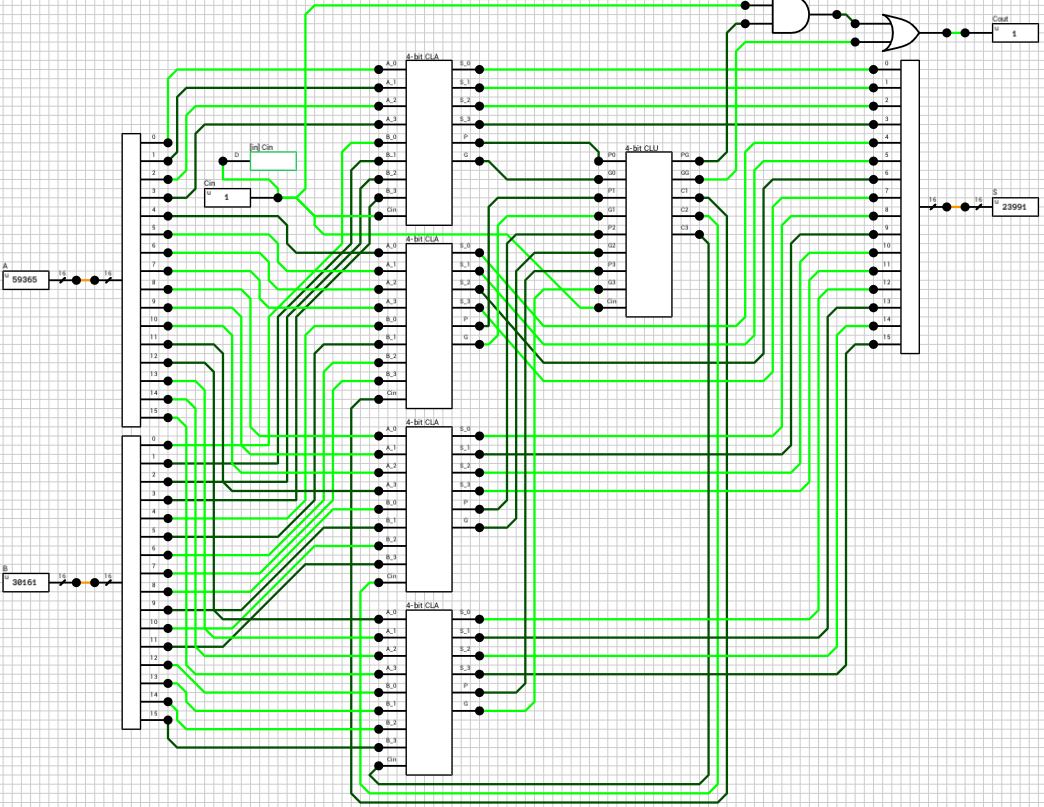
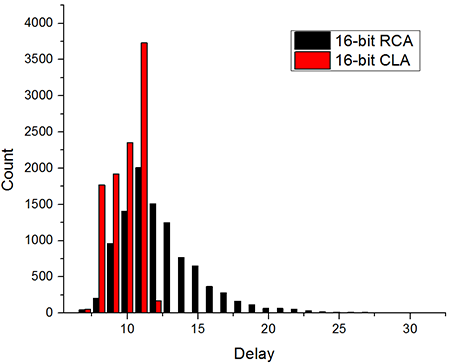
The final addition/subtraction is performed using a trimmed 16-bit CLA. The circuit is similar to the one presented in the previous article, with the only difference being that the 16-th bit of the result is used as the carry out of the addition and the sum is only 15 bits wide.
Step 4: Normalization
We now have all the parts necessary to reconstruct the result. Figure 10 shows the normalization block (norm_vector from the paper).
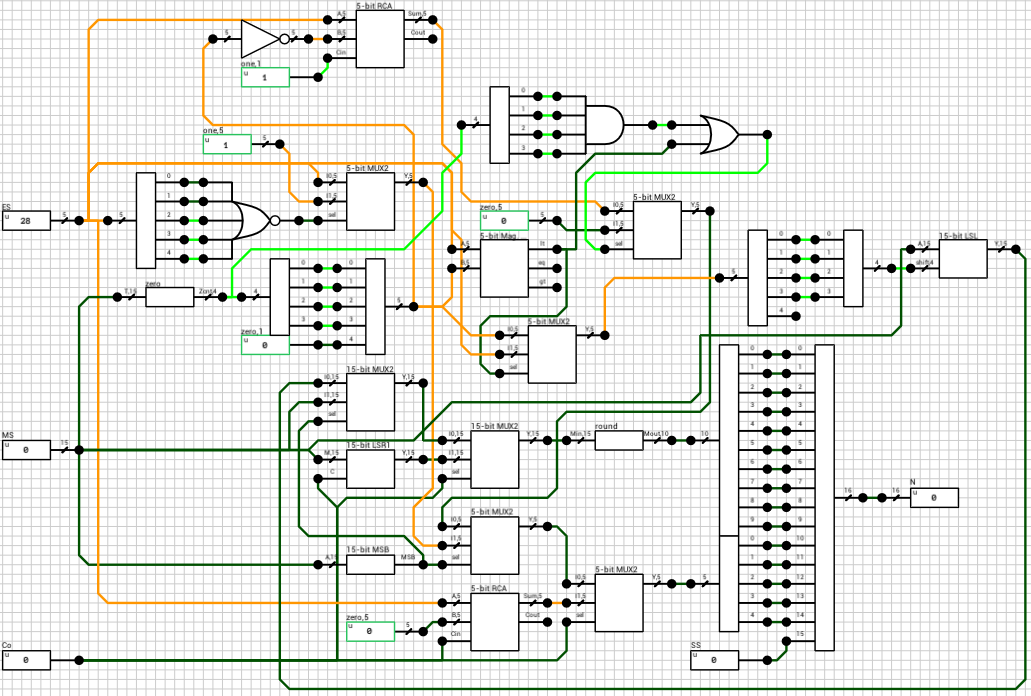
It might seem a bit more complicated than necessary so I’ll try to describe the circuit in pseudocode below. The job of this component is to normalize the mantissa and correct the exponent accordingly. It gets as inputs the sign of the result (SS), the exponent (ES), the mantissa (MS) and the carry out of the addition (Co). Note that this part is very different than the one found in the paper. I probably didn’t understand the VHDL correctly and my attempts to map it directly to circuit ended up producing invalid results. The circuit shown in figure 10 seems to behave correctly in all tested cases.
There are several cases to consider when normalizing the mantissa. The code below shows all of them in pseudocode (assume a combined 16-bit number ZX.YYYYYYYYYYYYYY, where Z = Co and X = MSB(M))
if Z == 1 then
E' = E + 1
M' = M >> 1 // M' = 1.XYYYYYYYYYYYYY
else
if X == 1 then
if E == 0 then // subnormal + subnormal = normal
E' = 1
M' = M // M' = 1.YYYYYYYYYYYYYY
else
E' = E
M' = M // M' = 1.YYYYYYYYYYYYYY
end
else
lz = leading_zeroes(M)
if E < lz or lz == 15 then
E' = 0
M' = M << E // Shift the mantissa to the left until the exponent becomes zero
else
E' = E - lz
M' = M << lz // Shift the mantissa to the left until an 1 appears on the MSB
endif
endif
endif
Hope it’s a bit more clear than the circuit :)
There are 2 special cases to consider. When adding two subnormal numbers, the result might end up being a normal (e.g. 0x0200 + 0x0200 = 0x0400 which is the smallest normal). In this case Z = Co = 0, X = MSB(M) = 1 and E = 0. The mantissa is already normalized (has an one at the MSB), so the exponent needs to be incremented to 1. If it’s left at 0, the result will be wrong when rounding the mantissa (see below).
The other case is then both X and Z are zero. In this case we have to shift the mantissa to the left until it becomes normalized or until the the exponent gets to 0. This can happen if the number of leading zeroes in the mantissa is larger than the exponent or if the mantissa is 0 (lz = 15). If the mantissa is zero at this point, it means that the result is 0 independently of the exponent (i.e 0x4000 - 0x4000 = 0 eventhough ES = 0x10).
Side note: The leading_zeroes component has been implemented using a 32k x 4-bit ROM.
Other than those 2 cases, the rest should be easily derived from any explanation on floating point addition.
The final step after calculating E' and M' is to round the mantissa. This involves ignoring the implicit bit (15-th bit) and rounding the guard bits. In order to keep things as simple as possible I decided to just cut off the guard bits, which is effectively rounding towards zero.
The final floating point adder circuit is shown in figure 11.
Thanks for reading. Comments and corrections are welcome.